傳統的Stable Diffusion WebUI只能用Nvidia GPU,AMD GPU,如果要使用Intel的GPU文生圖,只能另找方法,google好幾天不斷試錯還是做不出來(網路上一堆用linux的作法應該是不能用了),突然想到開vscode問AI,結果一天就做好,感嘆AI時代真的不一樣了
一. 先安裝python3.10, git
二. 建立虛擬隔離環境 (為了圖片放大功能搞壞環境,AI還是會出錯啊,好在AI有求必應,迅速給出步驟)
1. 删除旧环境
cd C:\AI\sd-openvino
Remove-Item -Recurse -Force .\venv
2. 创建新环境
python -m venv venv
.\venv\Scripts\Activate.ps1
3. 升级 pip
python -m pip install --upgrade pip
4. 安装核心依赖
pip install optimum[openvino,nncf]
pip install diffusers transformers accelerate
pip install gradio
pip install pillow
pip install peft
5. 验证安装
python -c "from optimum.intel import OVStableDiffusionPipeline; print('OK')"
python -c "from openvino.runtime import Core; print('Devices:', Core().available_devices)"
6. 运行 webui
python webui.py三. 模型需從Hugging Face下載並轉換成OpenVINO格式, 花很多時間試各種模型, 跟stable diffusion的模型比, 名稱一樣但文生圖成果不太一樣, 只能慢慢試
from optimum.intel import OVStableDiffusionPipeline
from pathlib import Path
import argparse
def download_and_convert(model_id, output_dir, device="GPU"):
"""下載並轉換模型為 OpenVINO 格式"""
print(f"📥 下載模型: {model_id}")
print(f"💾 輸出目錄: {output_dir}")
# 載入並轉換
pipe = OVStableDiffusionPipeline.from_pretrained(
model_id,
export=True,
device=device,
compile=False # 首次不編譯,讓首次使用時編譯
)
# 保存
output_path = Path(output_dir)
pipe.save_pretrained(output_path)
print(f"✅ 模型已保存到: {output_path}")
return output_path
def list_models(models_dir="./models"):
"""列出已下載的模型"""
models_path = Path(models_dir)
if not models_path.exists():
print("❌ 模型目錄不存在")
return
print("\n📦 已安裝的模型:")
print("-" * 60)
for model_dir in models_path.iterdir():
if model_dir.is_dir() and (model_dir / "model_index.json").exists():
size = sum(f.stat().st_size for f in model_dir.rglob('*') if f.is_file())
size_gb = size / (1024**3)
print(f" ✓ {model_dir.name} ({size_gb:.2f} GB)")
print("-" * 60)
def main():
parser = argparse.ArgumentParser(description="Stable Diffusion 模型管理工具")
parser.add_argument("--download", type=str, help="下載模型(Hugging Face ID)")
parser.add_argument("--output", type=str, default="./models", help="輸出目錄")
parser.add_argument("--name", type=str, help="模型名稱")
parser.add_argument("--list", action="store_true", help="列出已安裝的模型")
parser.add_argument("--device", type=str, default="GPU", help="設備(GPU/CPU/NPU)")
args = parser.parse_args()
if args.list:
list_models(args.output)
elif args.download:
model_name = args.name or args.download.split("/")[-1]
output_dir = Path(args.output) / f"{model_name}-openvino"
download_and_convert(args.download, output_dir, args.device)
else:
parser.print_help()
if __name__ == "__main__":
main()四. VAE很重要,不然人臉不能看,好在AI很快給出作法,做在webui.py裡,讚
五. Lora在openvino裡不是很好用,先暫時跳過
powershell
cd C:\AI\sd-openvino
.\venv\Scripts\Activate.ps1
python webui.py
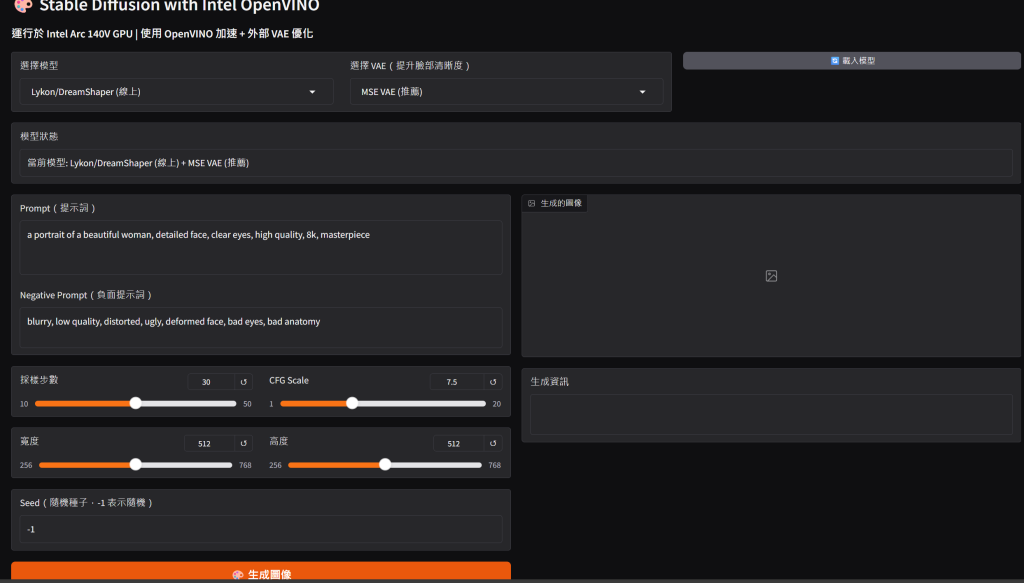
用Intel GPU文生圖,速度快,再也不用拿CPU慢慢跑了,讚啦
唯一的問題是prompt有字數限制72Tokens, prompt只能講重點, 若是有好一點的GPU的話跑SDXL模型,字數可以再多一點